A little food motivation
Spaghetti may be your family’s favorite weeknight thirty-minute meal (it is mine!), but it probably isn’t what you want served on your code’s plate. Like long, thin strands of linguine in a bowl, spaghetti code is often a tangled collection of seemingly endless flows that require way too much brain power to make sense of.

In Optibus’s backend, we started to see some of our code look and behave more and more like a plate of spaghetti. It certainly wasn’t like that from the beginning, but as the complexity of the features grew, the existing structure could not support new changes well.
So, we decided to ditch the spaghetti and apply a design pattern inspired by Italy’s next best thing:

Small and self-contained pieces of ravioli are stuffed with just the appropriate amount of rich and relevant content. Individual parts can be easily identified, and since their insides are clear and contained, they can be viewed atomically. For the manual editing feature in particular, this structure proved to be exactly what we needed to solve many of the code’s pain points. But enough with the pasta - let’s see exactly how!
Manual whaaaat?
As you probably already know, Optibus schedules are generated with a very cool and fast optimization algorithm. The bus schedule is essentially a table of timelines, where every row in the table is a vehicle, and the timeline is filled with the different driving events that the vehicle does in a day. These driving events can be trips carrying passengers, trips to bus parking lots or gas/recharge stations, and many more. Here is a sample of what a bus schedule looks like on the platform:
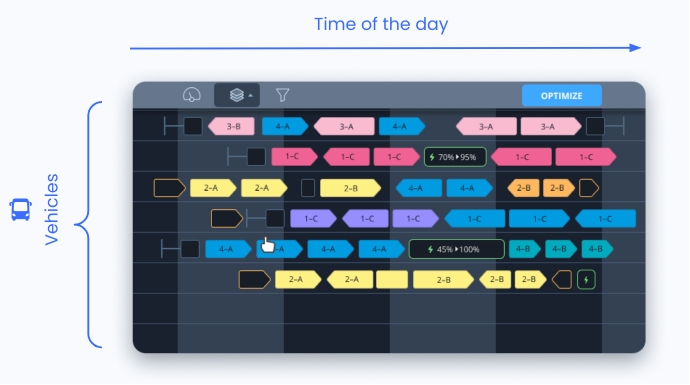
On the y-axis, each row is a different vehicle in the bus operator schedule. On the x-axis, we have the time of day increasing. The blocks represent driving events that the vehicles do at different times of the day.
Many times, bus operators need to tweak the schedule that the optimization algorithm spits out. They may want to add an event here, remove one there, make this event longer, swap these events between two vehicles…etc. For example, maybe the bus operator of the schedule shown above wants to remove the recharging event on the second vehicle (shown with an electricity icon) and create a new one later in the day. Or, maybe, the bus needs more time to recharge so the operator wants to make this event longer.
The manual editing feature is exactly what allows them to do that!
Now that it’s clear what this feature is, let’s hear a little story about how it was implemented ;)
But before, just so we’re on the same page…
Throughout this article, I reimagine the schedule above in a simpler way. Let’s take one row of the sample schedule and see how it simplifies:
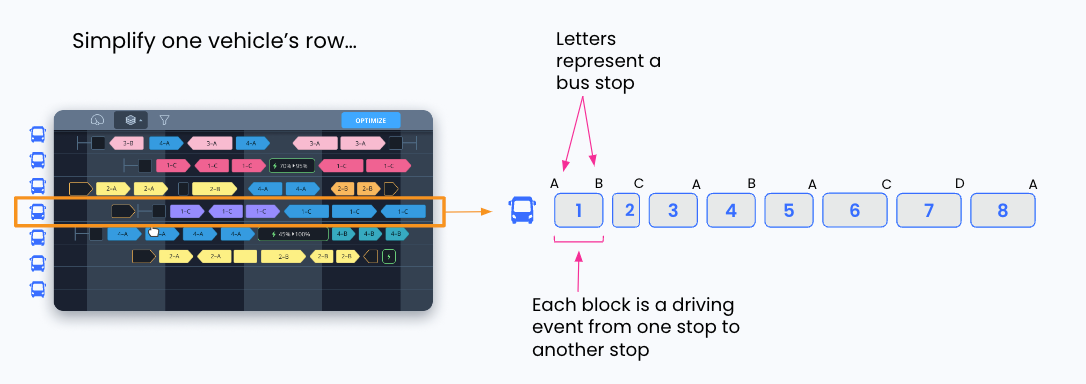
Here, I took the fifth bus and drew a simplified version of its eight events. I also showed the stops of each driving event. For example, the first event goes from stop A to B, the second from B to C, the third from C to A, etc. Note that the times of each event are not shown, but increase to the right.
Ok, now we’re ready :)
An extremely abridged but very telling story of how the manual edit feature was developed
Imagine we have a group of developers tasked with implementing manual editing, starting with actions dealing with a special type of driving event: deadheads. A deadhead is an event that simply takes a bus from one location to another (it’s “dead” because it has no passengers - just the driver).
Jessica’s strong start
Jessica is tasked with implementing the “add deadhead” feature. On the simplest schedule with one vehicle that makes one trip, adding a deadhead might look like this:
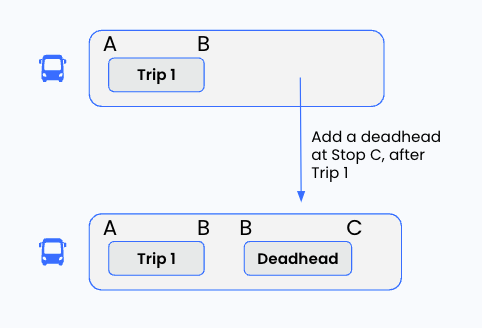
So, Jessica writes the function. It takes some basic inputs - where to add the deadhead in the bus’s day (the position) and the requested destination stop - and just adds a new event on the requested bus. In pseudocode, it looks something like this:

After covering lots of cases and writing lots of unit tests, Jessica finishes the task. Yay!
Jeremy’s smooth sailing
A week later, Jeremy is tasked with adding the “remove deadhead” function. In thinking about the problem, he quickly realizes the removal is actually a slightly complex process. First, he needs to simply remove the requested event. For example, say the user wants to remove the deadhead (DH) going from stop B → C on this bus’s timeline:
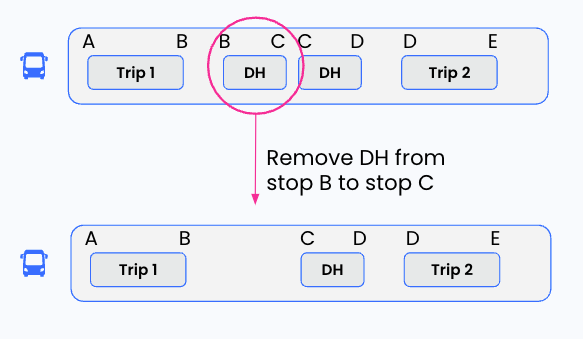
However, as you can see, this removal might have caused a geographical gap in the schedule!
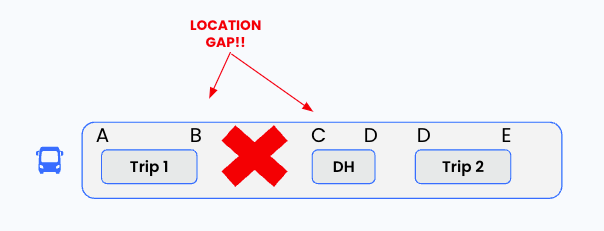
This means there is a “jump” in bus stops. Since buses can’t magically teleport from one stop to the next, Jeremy needed to implement logic to make sure that the schedule makes sense even after the removal.
In the specific case shown above, Jermey’s code removes an additional nearby deadhead, in order to replace both with a different, valid deadhead. The final result:
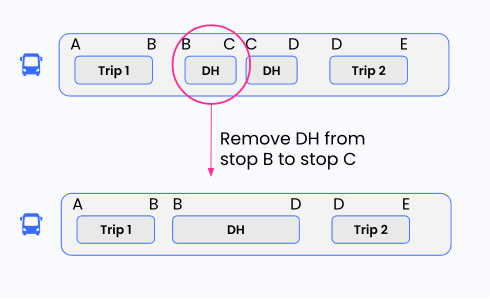
At the end of the day, his functions looked something like this:

In the third step of his code, Jeremey is happy to see that he could reuse one of Jessica’s functions, add_deadhead. So far, the code looks good at a high level, with a simple flow:
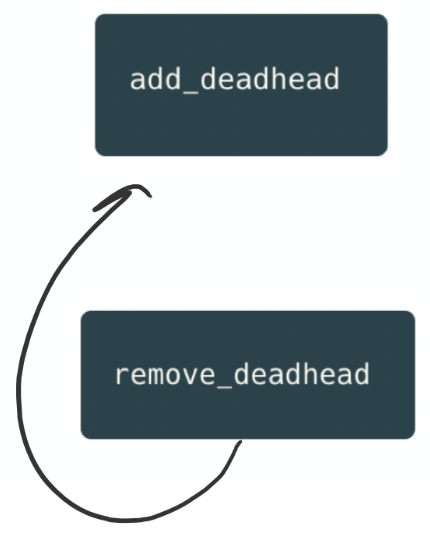
Silvetta’s rocky road
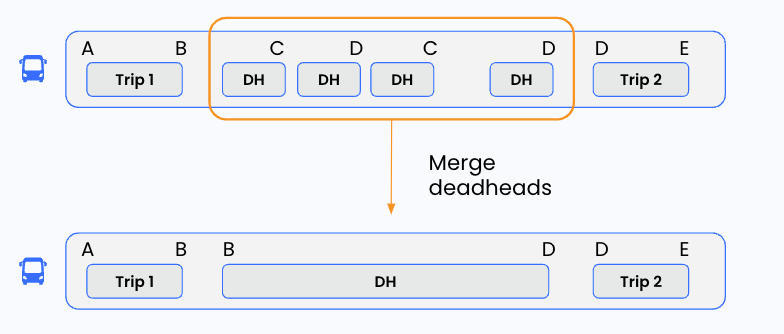
Silvetta is tasked with the next requested feature: merging deadheads. That is, the customer wants to be able to select many consecutive deadheads and squish them into one. For example, for the bus below we want to merge four deadheads into one. The desired stops are implied – the merged deadhead should begin at the first deadhead’s origin stop (B) and end at the last deadhead’s destination stop (D).
Following in Jeremy’s footsteps, she too realizes there is an opportunity to reuse code. She thinks:
In order to merge a group of deadheads, I will first remove each of them, and then replace them with a new one.
So, using Jeremy’s remove function, she writes something along the lines of:

And now the flow looks like:
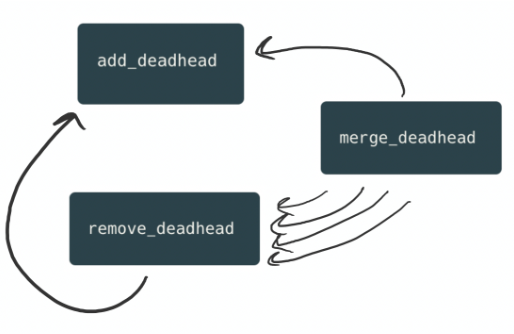
It sounds like a great plan, but Silvetta has run into a few problems.
First, recall that Jeremy’s function doesn’t just remove a single deadhead - it also might remove an additional deadhead and add a new one, if a geographical gap is created. So, using his function as-is causes some weird side effects and funky behavior. Silvetta has decided it’s no problem, she’ll just call Jeremy’s function with a flag indicating that geographical gaps are okay - there’s no need to “fix” them.
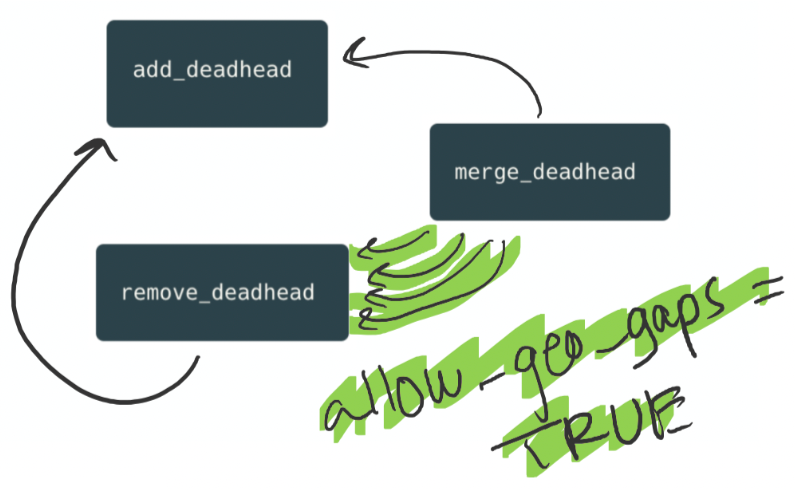
But then she runs into an even more unexpected problem! It turns out that last week, Sarah dealt with a manual edit bug and, as a result, added a verification in add_deadhead and remove_deadhead that throws an error when the schedule has any geographical gaps by the end of the action. This is to prevent users from being able to continue working on the schedule if it reached an invalid state by accident.
So, Sarah’s additions to Jeremy and Jessica’s work looks something like this:

Now, of course Silvetta isn’t trying to create broken schedules with location gaps - she just needs to support this intermediate step before her final step, where she adds the needed deadhead. So, she adds one more flag to both functions to support her function. One flag tells remove_deadhead to not fix geographical gaps, and the other flag skips the newly added validations.
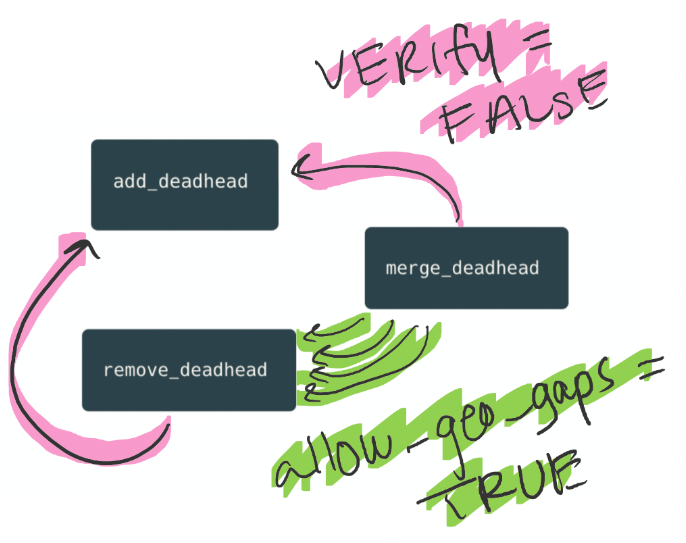
Our visualization got a bit messier, didn't it?
And now imagine more functions get added down the road, and maybe more flags and more parameters would need to be added to the existing functions in order to make them “fit” our new ones. In many cases, we’d want to reuse our functions, but constantly need to refactor them to support more contexts and a variety of constraints.
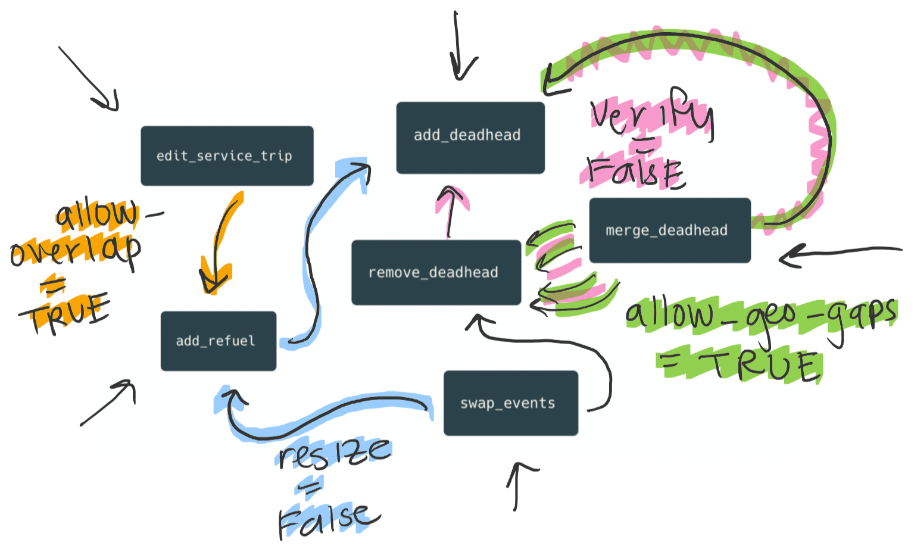
A recipe for spaghetti
Let’s take a step back. What happened here that got us to this point? It seems that as we added new actions, we tried to do two things at once. On the one hand, we made these functions very thorough, covering every possible combination of constraints of the process from start to finish. Great! How comprehensive of us. On the other hand, we tried to reuse existing code as much as possible. Also great! We write code that follows the DRY (don’t repeat yourself) coding principle.
These seemingly good things actually came into conflict here. Each function met the specifications of the feature, giving a smart solution to all the cases. But, we found ourselves trying to build new actions using only parts of the existing ones. That is, when we tried to chain existing functions together, we ended up having to add more and more conditional pathways to support new use cases and intermediate steps.
This addition of intertwined pathways, flags and parameters to functions are key ingredients of spaghetti code! And this, of course, is not an ideal flow for our brains to have to follow when we debug or develop. All the squiggly arrows and conditionals are warning signs that, while the code may be working and thorough, the design isn’t right. This is the time to take a step back, look at the problem at a higher level and rethink the solution.
The raviolization
Let’s think of a different way to visualize the add, remove, and merge deadhead actions:
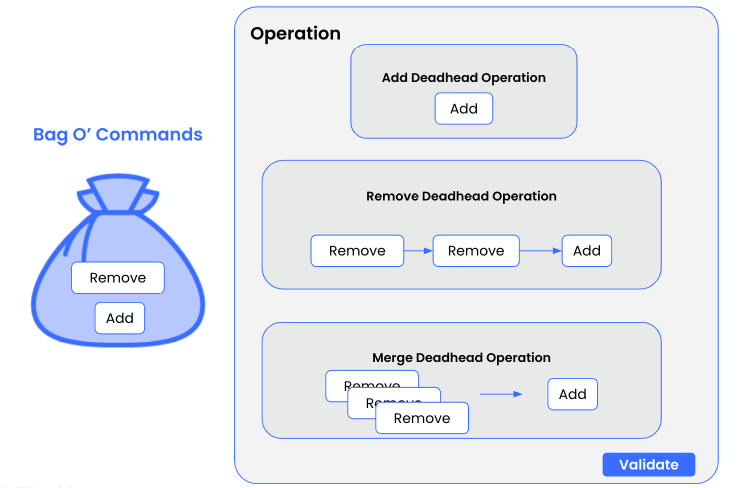
On the left, we have a bag of “commands” that do one small single action. On the right, we have “operations”, which chain together these commands, implementing any context-specific logic needed to glue them together. All the operations, in yellow boxes, share a global space (gray box) as well, where we can call actions that should happen after operations finish, not commands. In our story, the validation for geographical gaps fits in this scope.
The Add Deadhead Operation is the simplest, it just needs to use the “add deadhead” command.
The Remove and Merge Operations use both the add and remove commands. However, they use them differently. As we saw from the earlier stories, the Remove Operation needs to use the remove command, then potentially use the remove command again, then maybe use the add command. The Merge Operation knows exactly how many times it needs to use the remove command, and to finish off with an add command. Unlike before, this context-specific logic on how to use “remove” or “add” has been decentralized from the actions themselves. Instead, we have a higher-level component, the “operation”, which controls how to piece the building blocks together.
The goal of this design is for the commands to be perfect little ravioli: self-contained, atomic, and easily black-boxed when thinking of an abstract sequence of events. The operations are then just bigger ravioli made up of these smaller ones, with their own special filling!
Now, isn’t that a nicer way of thinking about our manual edit problem? When adding more manual edit operations, we simply look in our bag of commands, add new commands if needed, and then write the logic that creates the sequence of events.

Conclusion
We all know that a one-pot spaghetti is a much faster meal to prepare than hand-crafted ravioli (we’re not talking store-bought here, people), and when you’re working in a high-paced, intense start-up environment, let’s face it -
But in recent years, it’s become increasingly important at Optibus to have a product that scales and grows efficiently. From the technical perspective, this can mean taking a step back and identifying the code in your codebase that makes your brain hurt, and finding whatever metaphors and abstractions fit your problem better. I hope that this post has inspired you to do one of three things: come join us at Optibus to solve fun and challenging problems with good design, feel inspired to redesign some of your own code, or at least make some home-made, plant-based ravioli :)
This post is dedicated to a dear friend and colleague, Nimrod Pansky, who may or may not have loved ravioli, but sure did love the command/operation re-design.