
At Optibus, we’ve created a cloud-based platform that solves the very challenging problem of planning and scheduling public transportation (mass transit). Our platform is used to plan citywide networks of routes and timetables, and then schedule the movement of every vehicle and driver during every minute of the day. This can result in thousands of daily service trips, vehicles, and drivers being scheduled. We have developed many capabilities to solve these challenges, including the development of distributed optimization algorithms that require immense computational power. These algorithms are triggered ad hoc when such complex optimization tasks are requested.
In our case, such tasks are triggered in response to a transportation planner setting up their rules and preferences, applying their expertise, and requesting to create an optimized plan. This will happen hundreds or thousands of times during the day, but as you can imagine, the usage pattern is very volatile and unpredictable. This makes capacity planning very difficult because the demand for resources fluctuates rapidly, creating multiple spread bursts of CPU demand.
Applying the classic scale-out approach using industry standards, such as Kubernetes, is not well-suited when a burst of computational power is required for a very short period that does not have constant or predicted usage patterns. The reasons being:
- Either you must have many nodes standing by waiting to absorb the burst, which is a significant cost waste
- Or you need to spawn many nodes at the same time, which requires waiting (and paying) for the boot time of the machines and the time during the scaling down of the nodes once the pods have been removed
On top of that, Kubernetes was not built to manage instant increases and decreases of tens or hundreds of pods required for only a few tens of seconds. It is more suited for typical scale requirements that rely on metrics, such as CPU, memory load, task queue backlog, etc. These metrics are spread across multiple machines that serve thousands of parallel requests. As a result, they don’t tend to have a sudden sharp steep curve (for the math fans this means a uniformly continuous function) as the load each new request creates is amortized. However, in our case, a new task can be viewed as the equivalent of having an increase of 10,000 new parallel requests within a few seconds, which requires a different kind of scaling logic.
This is why we chose to use AWS Lambda (Function as a Service), applying a producer-consumer pattern that works very well for this case. The advantages of using Lambda for this purpose includes:
- Fast “cold start” start time – the time it takes to spawn a new instance is sub-second, unlike when spawning a new node (and all the pods on it) in Kubernetes, which can take even 30 seconds
- Immediate tear down – once the work is done you stop paying for resources. When using Kubernetes, terminating pods and nodes is not immediate, it is planned for more constant demand, so it doesn’t make sense to take down the instances right after the work is done
- All scaling considerations are hidden away and handled by AWS – even though Kubernetes simplifies this as well, at the end of the day non-trivial tuning is still required to manage the cluster
We have planned this task in a way that we can have one data set, and the computational work can be done on small chunks and aggregated together as a single result (scatter-gather pattern).
The outline of the steps goes like this:
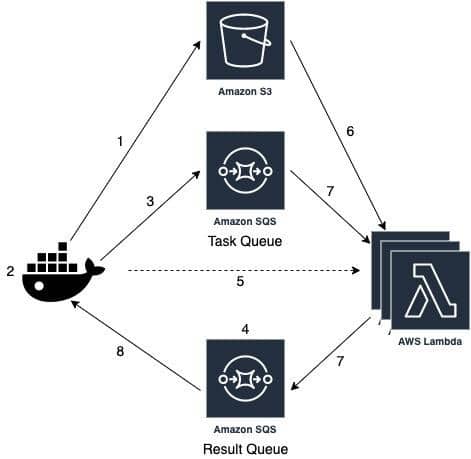
- Upload the required optimization task data once to S3
- Calculate the optimal number of distribution of tasks and the optimal number of Lambda workers
- Populate a stack index SQS queue with integers matching the optimal number of tasks, where each integer represents the index of the task the consumer of this event should do. The code of the task execution only requires this index and the uploaded data in order to execute
- Create an empty task result SQS queue
- Spawn the optimal number of Lambda instances using invoke (which can be thousands), passing the information required to find the uploaded data in S3, the task index SQS queue, and the task result SQS queue
- The Lambda instances are downloading the task data from S3
- The Lambda instances start taking tasks from the queue (index), runs its calculation, and returns the result through the SQS queue. It does so until the task queue is empty
- The client side that invoked the Lambda instances and created the queues is pulling results from the task result queue as they come and aggregates the results
Using this flow, we are able to pay for exactly the required computational time and take advantage of AWS Lambda “cold start” (spin-up time) of sub seconds.
One thing to notice is that this pattern stops being effective when the execution time becomes significantly high, in a way that makes the overhead time it takes to spawn new nodes (“cold start”) and pods and the corresponding tear down overhead minor in the process. As clearly AWS Lambda has its cost, and it is significantly higher than paying for EC2 instances, especially when you take spot instances into account.
Read more:
➤Continuous Deployment in Mission-Critical Enterprise SaaS Software
➤Can We Optimize City Transportation Better Than A Museum Robber Could?
➤Optibus Raises $107 Million and Launches Geospatial Suite to Help Cities Shape the Future of Urban Mobility
➤Optibus Engineering Blog







